
-
- Downloads
Add remaining content and figures
Showing
- portal/content/articles/data.md 190 additions, 0 deletionsportal/content/articles/data.md
- portal/content/articles/experts.md 255 additions, 0 deletionsportal/content/articles/experts.md
- portal/content/articles/science.md 163 additions, 0 deletionsportal/content/articles/science.md
- portal/content/articles/software.md 80 additions, 0 deletionsportal/content/articles/software.md
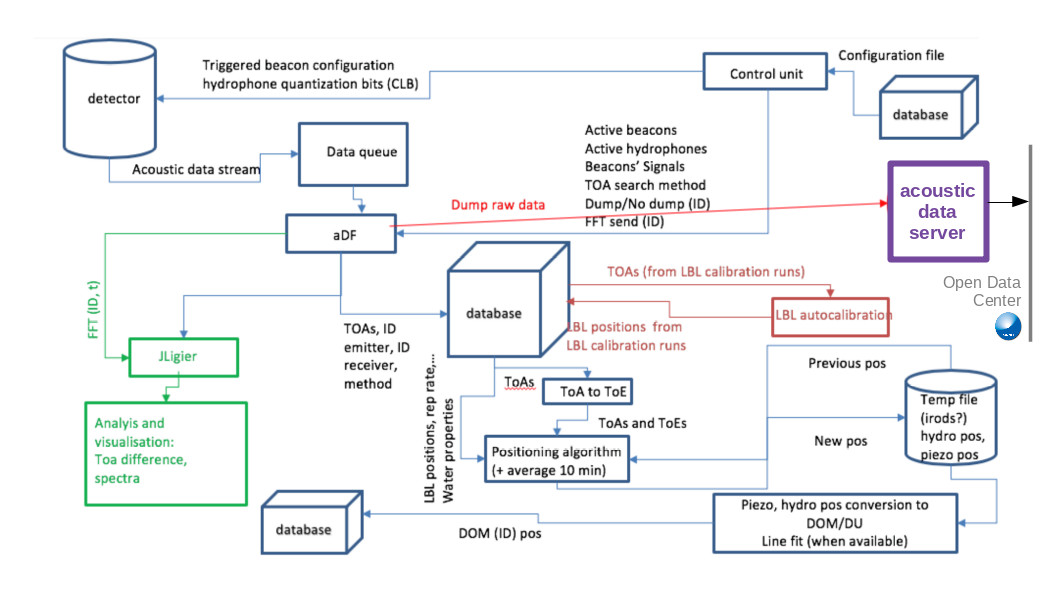
- portal/static/figures/Acoustic_data.png 0 additions, 0 deletionsportal/static/figures/Acoustic_data.png
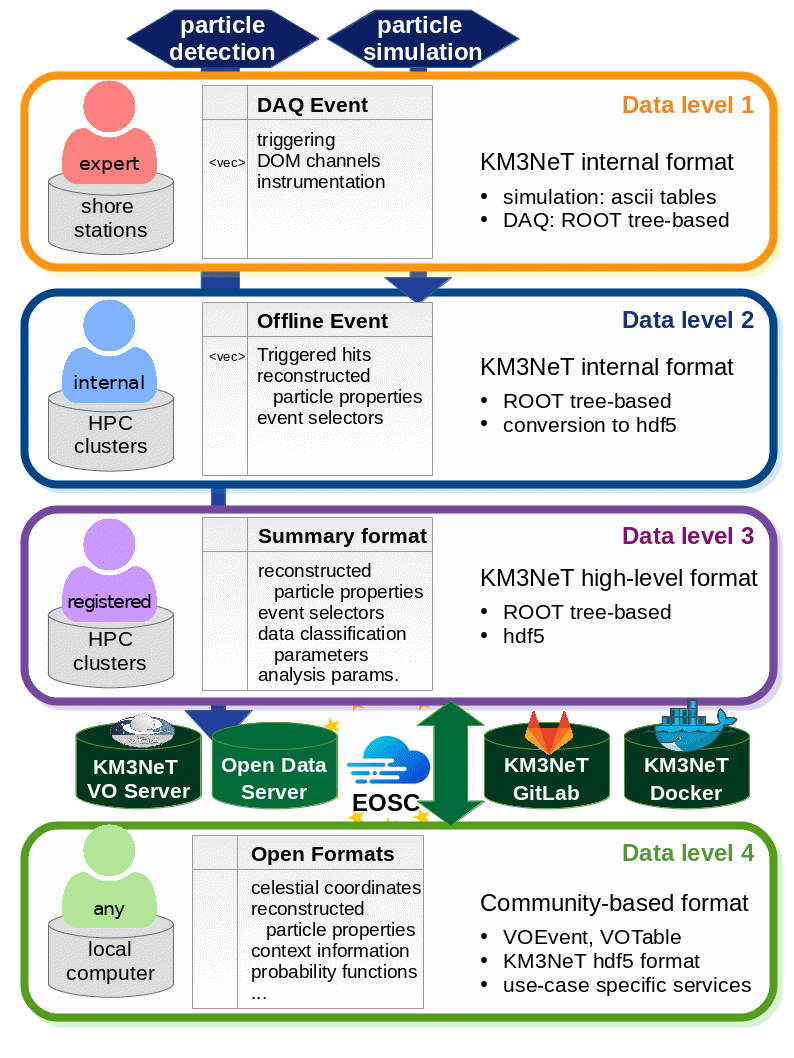
- portal/static/figures/Data_levels.gif 0 additions, 0 deletionsportal/static/figures/Data_levels.gif
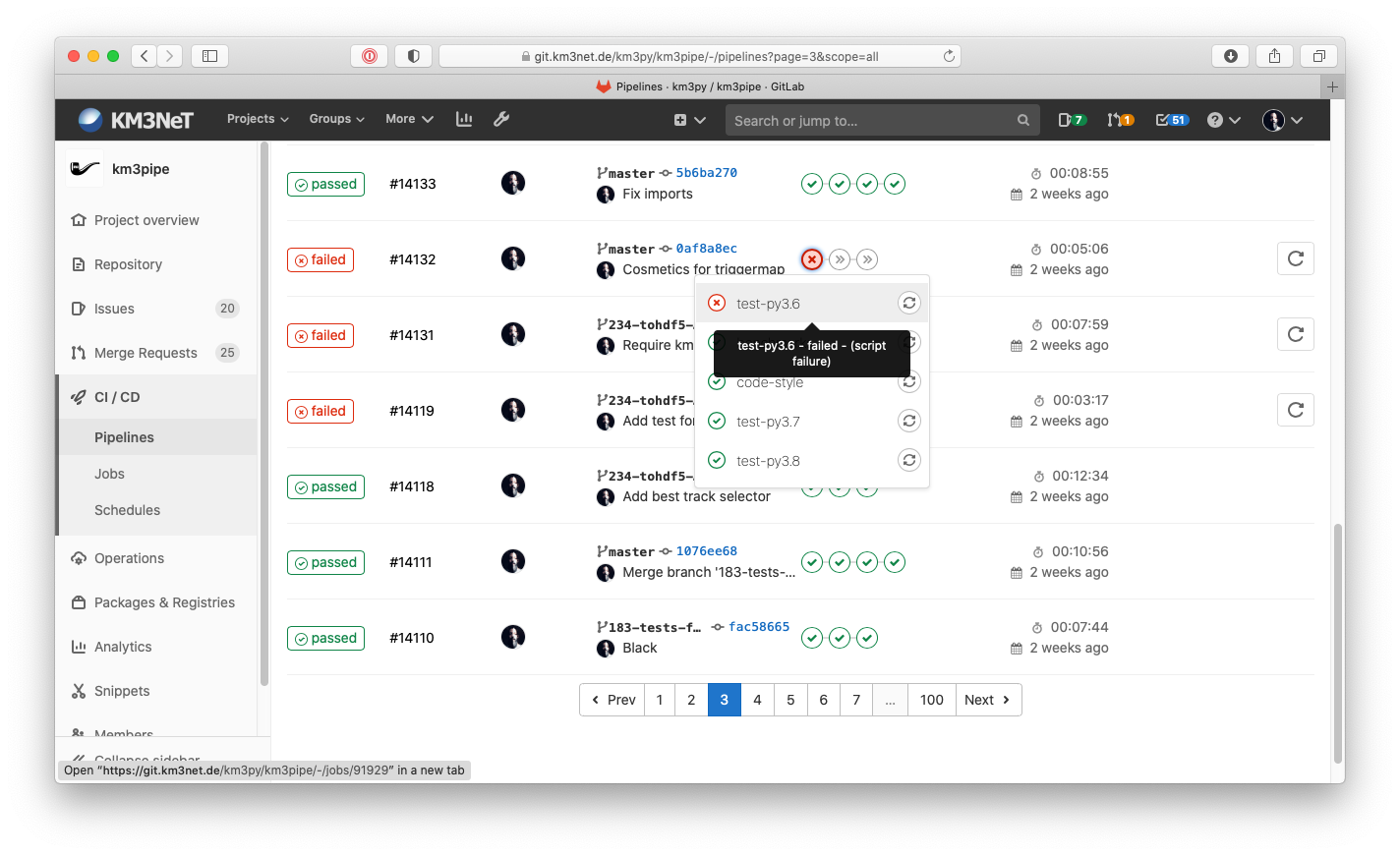
- portal/static/figures/ci-pipelines.png 0 additions, 0 deletionsportal/static/figures/ci-pipelines.png
portal/content/articles/data.md
0 → 100644
portal/content/articles/experts.md
0 → 100644
This diff is collapsed.
portal/content/articles/science.md
0 → 100644
This diff is collapsed.
portal/content/articles/software.md
0 → 100644
portal/static/figures/Acoustic_data.png
0 → 100644
{kind=link}
204 KiB
portal/static/figures/Data_levels.gif
0 → 100644
{kind=link}
126 KiB
portal/static/figures/ci-pipelines.png
0 → 100644
{kind=link}
311 KiB